Amazon Elastic Beanstalk provides a PaaS similar to Google AppEngine, bundling many of their existing offerings such as Elastic Compute Cloud (EC2), Simple Storage Service (S3), Simple Notification Service (SNS), Elastic Load Balancing, Auto Scaling, and monitoring using Cloud Watch into a simple to use service. Additionally, other Amazon services such as SimpleDB, Relational Database Service (RDS), Simple Queue Service (SQS) may be used as well.
Currently, Elastic Beanstalk provides a Java-based application container with Apache Tomcat as the work horse. All you have to do is to deploy a standard Java WAR file containing your web application.
Simply create a Java web application with Spring MVC, Grails, OSGi, Eclipse RAP, or any other of the numerous Java web frameworks and upload it using the AWS web console.
Additional containers for other platforms such as Ruby, Python or PHP may follow later, but as Tomcat hosts standard Java WAR files, anything with a Java implementation may be run. Ruby apps based on Rails or Rack using Warbler and JRuby, Python apps using Jython, even PHP apps can be made to run on Beanstalk.
In this blog post, I’ll dive into the inner workings of a Beanstalk server instance and poke around its internals. I invite you to come along for the ride.
Accessing your instance
The first step in dissecting a Beanstalk instance is getting access via SSH.
In order to acces your running instance(s), you first need to configure the SSH key pair to be used:

Configuration dialog in Elastic Beanstalk web console
Enter the name of a key pair as configured in your EC2 web console. See the EC2 guide and the description in the Elastic Beanstalk guide for details on creating and configuring a key pair.
Setting the key pair requires a restart of your Beanstalk environment, which may take a couple of minutes.
Finally look up your instance id and get the instance’s hostname. Connecting to the server is now as simple as this:
ssh -i .ec2/mykeypair.pem ec2-user@ec2-184-72-134-2.compute-1.amazonaws.com
Please note, that you need to connect as user ec2-user, root access can be reached using the command
sudo su -
Getting around your instance
The first steps are to collect some interessting facts. The instance uses a Amazon Linux AMI (release 2010.11.1 (beta), README). The AMI id for the ElasticBeanstalk-Tomcat6-32bit is ami-7609f81f, the kernel id is aki-407d9529. The instance is EBS-based and there is no ephemeral storage. Currently, Beanstalk is only available in the US East zone.
Software
The process list reveals: along with Apache Tomcat, Beanstalk uses the venerable Apache Web Server. Additional software includes Bluepill for basic process monitoring, and Amazons own HostManager (see below), which is run within a Thin web server.
Network setup
Elastic Beanstalk scales EC2 instances as needed. Therefore the first target is a load balancer provided by Elastic Load Balancing. Each instance runs Apache as the front end on port 80, with web request being reverse proxied into Tomcat on port 8080. Requests for URI /_hostmanager are forwarded to HostManager on port 8999.
CloudWatch performs health checks by periodically requesting the root page (URI /) of your application. Both health check URI and frequency are configurable. If an instance is no longer available or the load changes, CloudWatch starts or stops instances.
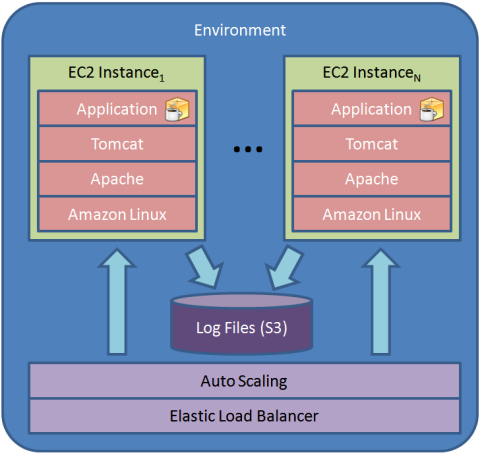
[Image from AWS Elastic Beanstalk Concepts blog post]
HostManager
Local instance management is performed by Amazons HostManager. HostManager is a Ruby application based on Rack and running in a Thin server on port 8999. It receives requests on URI /_hostmanager.
Some examples from the access log:
72.21.217.96 (72.21.217.96) - - [21/Jan/2011:22:00:45 +0000] "POST /_hostmanager/tasks HTTP/1.1" 200 368 "-" "AWS ElasticBeanstalk Health Check/1.0"
10.223.61.43 (10.223.61.43) - - [21/Jan/2011:22:01:05 +0000] "GET /_hostmanager/healthcheck HTTP/1.1" 200 90 "-" "ELB-HealthChecker/1.0"
10.122.19.154 (10.122.19.154) - - [21/Jan/2011:22:01:11 +0000] "GET /_hostmanager/healthcheck HTTP/1.1" 200 90 "-" "ELB-HealthChecker/1.0"
10.223.61.43 (10.223.61.43) - - [21/Jan/2011:22:01:36 +0000] "GET /_hostmanager/healthcheck HTTP/1.1" 200 90 "-" "ELB-HealthChecker/1.0"
10.122.19.154 (10.122.19.154) - - [21/Jan/2011:22:01:42 +0000] "GET /_hostmanager/healthcheck HTTP/1.1" 200 90 "-" "ELB-HealthChecker/1.0"
72.21.217.96 (72.21.217.96) - - [21/Jan/2011:22:01:46 +0000] "POST /_hostmanager/tasks HTTP/1.1" 200 368 "-" "AWS ElasticBeanstalk Health Check/1.0"
10.223.61.43 (10.223.61.43) - - [21/Jan/2011:22:02:07 +0000] "GET /_hostmanager/healthcheck HTTP/1.1" 200 90 "-" "ELB-HealthChecker/1.0"
10.122.19.154 (10.122.19.154) - - [21/Jan/2011:22:02:13 +0000] "GET /_hostmanager/healthcheck HTTP/1.1" 200 90 "-" "ELB-HealthChecker/1.0"
10.223.61.43 (10.223.61.43) - - [21/Jan/2011:22:02:38 +0000] "GET /_hostmanager/healthcheck HTTP/1.1" 200 90 "-" "ELB-HealthChecker/1.0"
10.122.19.154 (10.122.19.154) - - [21/Jan/2011:22:02:44 +0000] "GET /_hostmanager/healthcheck HTTP/1.1" 200 90 "-" "ELB-HealthChecker/1.0"
72.21.217.96 (72.21.217.96) - - [21/Jan/2011:22:02:47 +0000] "POST /_hostmanager/tasks HTTP/1.1" 200 368 "-" "AWS ElasticBeanstalk Health Check/1.0"
Files
HostManager is installed in /opt/elasticbeanstalk/srv/hostmanager. A file list can be found here. /opt/elasticbeanstalk/lib also contains a full Ruby 1.9.1 installation.
Some log files can be found at /opt/elasticbeanstalk/var/:
/opt/elasticbeanstalk
/opt/elasticbeanstalk/var
/opt/elasticbeanstalk/var/state
/opt/elasticbeanstalk/var/state/hostmanager.pid
/opt/elasticbeanstalk/var/state/healthcheck
/opt/elasticbeanstalk/var/tmp
/opt/elasticbeanstalk/var/log
/opt/elasticbeanstalk/var/log/LogDirectoryMonitor.log
/opt/elasticbeanstalk/var/log/DaemonManager.log
/opt/elasticbeanstalk/var/log/bluepill.log
/opt/elasticbeanstalk/var/log/hostmanager.log
/opt/elasticbeanstalk/var/log/ApplicationHealthcheck.log
/opt/elasticbeanstalk/var/log/CatalinaLogMonitor.log
Final words
That’s all for today’s blog post. Further posts will take a closer look at HostManager and deployment including the application setup sequence.
I’m looking forward to any feedback and additional information.
Maybe we can even hack HostManager to accept other application containers, e.g. for OSGi applications.
 The slides are available under the CreativeCommons license BY-NC-SA.
The slides are available under the CreativeCommons license BY-NC-SA.






